FAST-EQA
Efficient Embodied Question Answering with Global and Local Region Relevancy
Haochen Zhang*, Nirav Savaliya, Faizan Siddiqui, Enna Sachdeva
Honda Research Institute USA, *Carnegie Mellon University
📄 Paper 💻Code
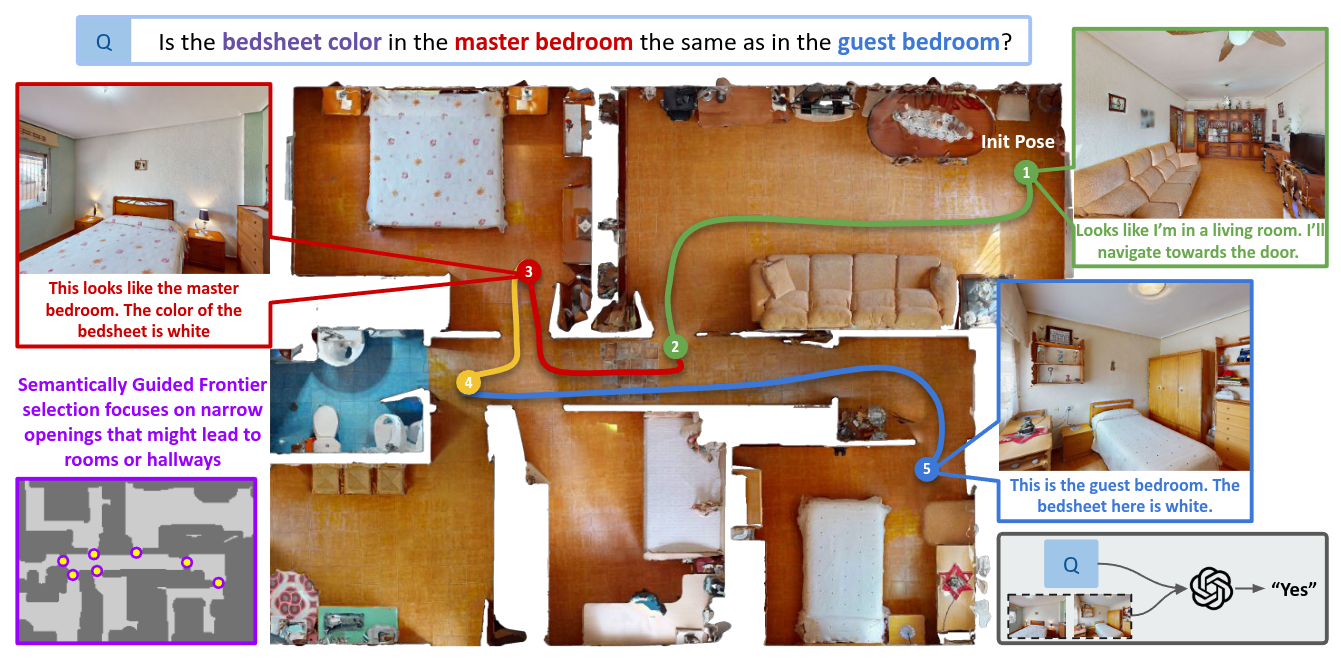
Overview
Embodied Question Answering (EQA) requires an agent to navigate a 3D environment and answer natural language questions using visual observations. This demands perception, spatial reasoning, semantic understanding, memory management, and efficient exploration.
Existing approaches often struggle with:
- Inefficient exploration policies
- Unbounded or noisy memory
- Slow inference due to heavy vision-language reasoning
- Difficulty handling multi-target questions
FAST-EQA introduces an efficient and scalable framework that combines:
- Question-conditioned global exploration
- Target-aware local search
- Bounded visual memory
- Chain-of-Thought reasoning for robust answering
The result is a faster, more accurate embodied QA agent that scales to long-horizon tasks.
Method Overview

FAST-EQA operates in four main stages:
1. Question Parsing
Given a question, an LLM extracts:
- Visual Targets (T) – objects or attributes to inspect
- Relevant Regions (R) – areas likely to contain those targets
Example:
"Are the bedsheets in the master and guest bedrooms the same color?"
- Targets: bedsheets (master bedroom), bedsheets (guest bedroom)
- Relevant Regions: master bedroom, guest bedroom
This decomposition guides exploration from the start.
2. Global Relevance Exploration (GRE)
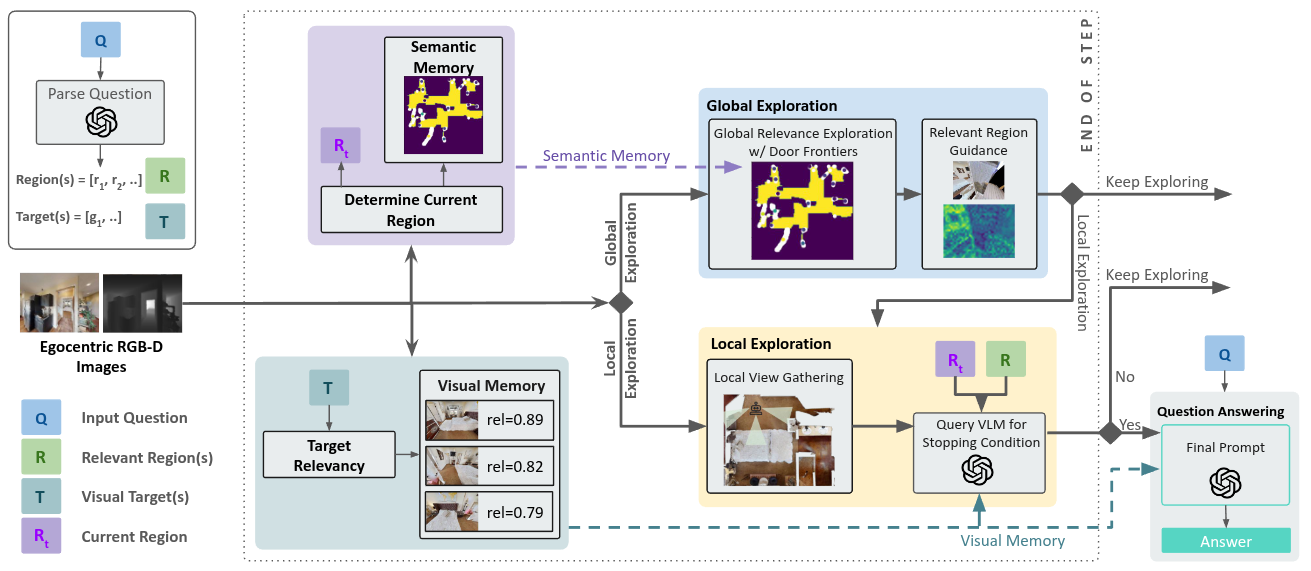
Instead of standard frontier exploration, FAST-EQA prioritizes semantically meaningful frontiers.
Key ideas:
- Detect narrow openings (doors, hallways) from occupancy maps
- Treat them as region transitions
- Rank frontiers based on proximity to relevant regions
- Move toward regions likely to contain answer evidence
This allows the agent to efficiently reach important areas without exhaustively exploring the full map.
3. Local Relevance Exploration (LRE)
Once inside a relevant region:
- The agent collects panoramic observations
- Visual observations are evaluated for target relevance
- A stopping condition checks whether enough evidence has been gathered
This prevents unnecessary wandering and reduces redundant observations.
4. Bounded Visual Memory
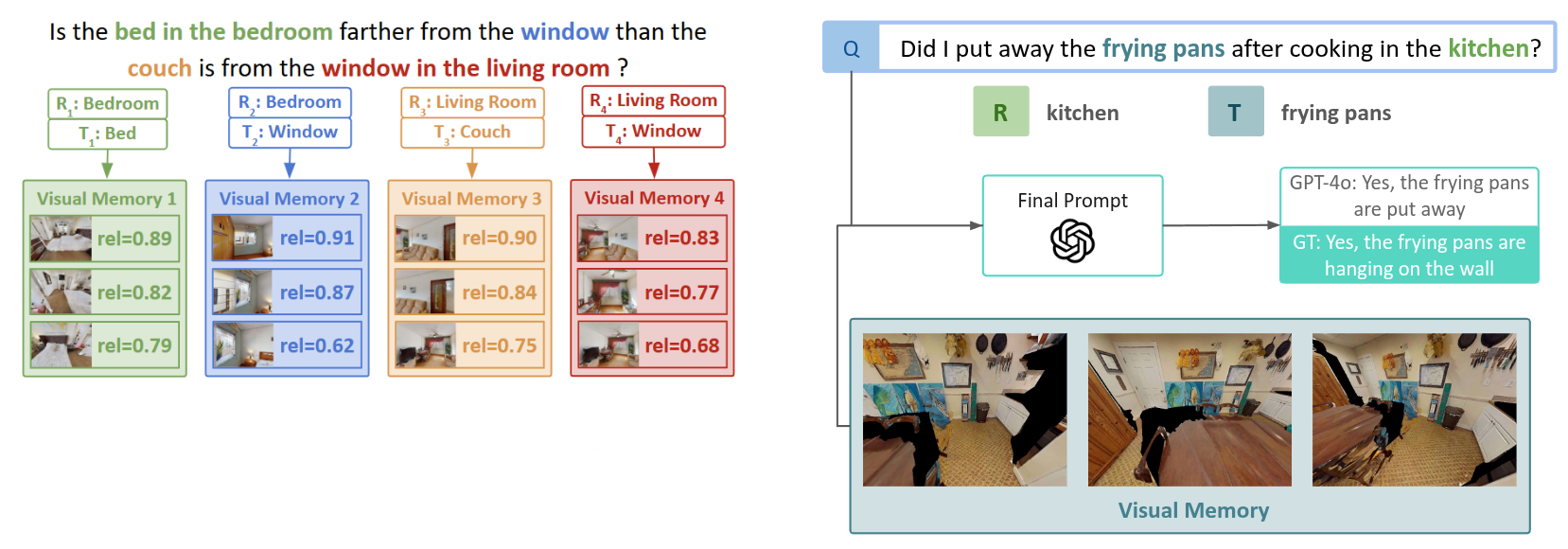
To maintain efficiency, FAST-EQA uses a fixed-size memory per target.
Each observation is scored using:
- CLIP similarity between image and target text
- A generative VLM relevance score
Only the top-k most relevant observations per target are stored.
This ensures:
- Constant memory size
- Reduced noise
- Fast inference
- Improved reasoning quality
5. Chain-of-Thought Answering
Once exploration completes:
- The stored memory is passed to a large vision-language model
- A structured Chain-of-Thought prompt guides reasoning
- The model produces the final answer
This improves:
- Multi-step reasoning
- Multi-target comparison
- Interpretability
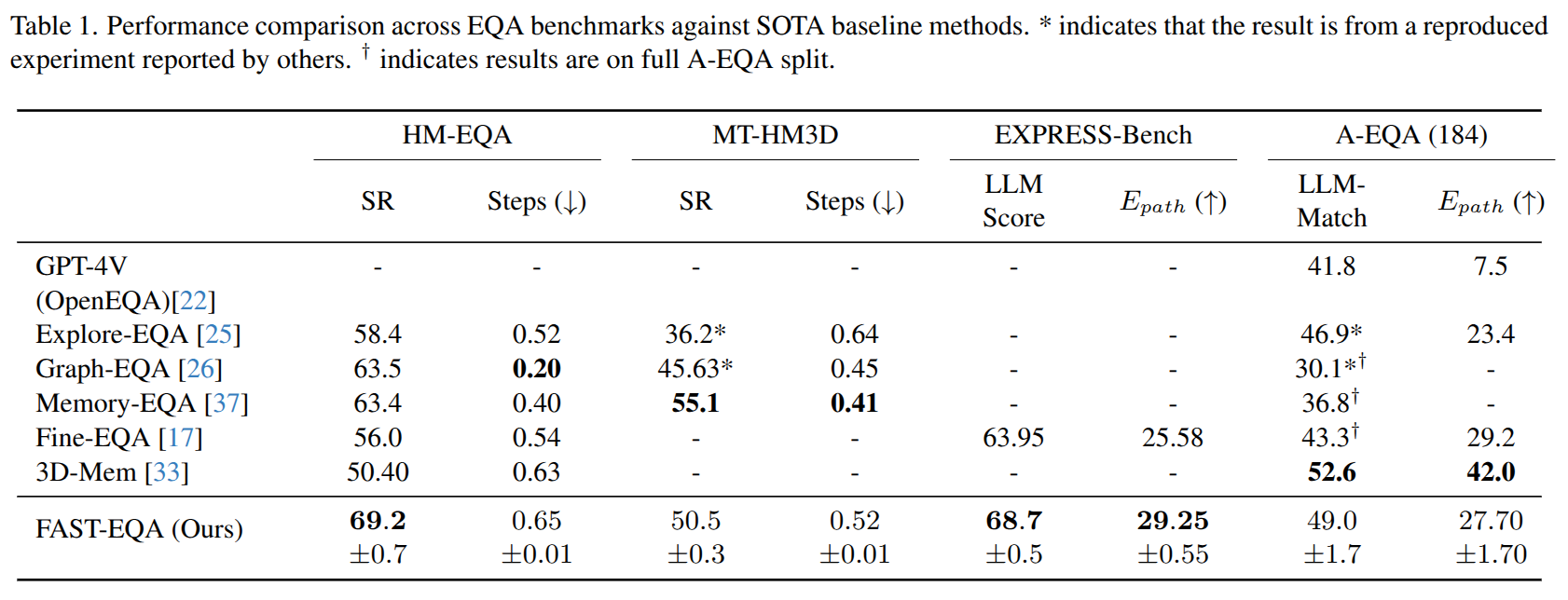
Experimental Results
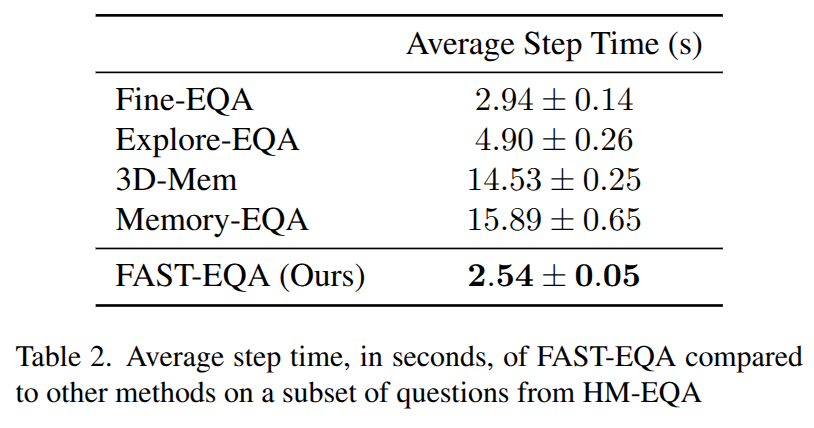
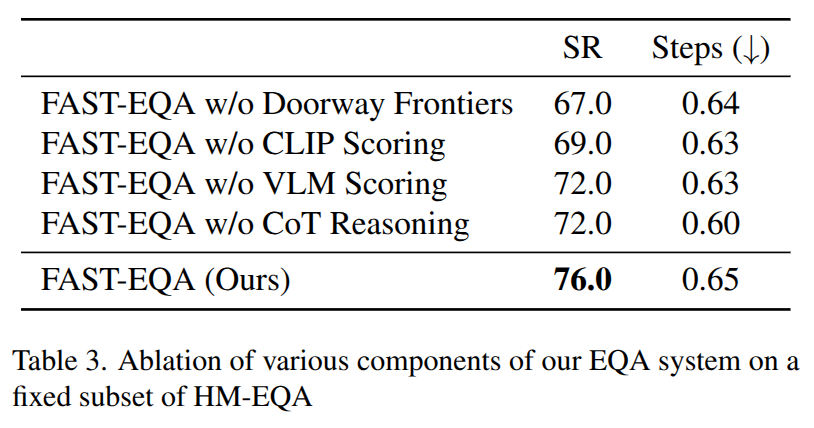
Links
Paper: https://arxiv.org/abs/2602.15813
Code: Coming Soon
Cite our work:
If you find this work useful, please consider citing:
@article{fasteqa2026,
title={FAST-EQA: Efficient Embodied Question Answering with Global and Local Region Relevancy},
author={Haochen Zhang and Nirav Savaliya and Faizan Siddiqui and Enna Sachdeva},
booktitle = {Winter Conference on Applications of Computer Vision (WACV), 2026},
year={2026}
}